
For a file that has repeating data for fields that are in single column, here are the steps:
John Smith
123 Main St
Chicago
Illinois
Jane Smith
234 Main St
Atlanta
Georgia
Create a text schema (if file is text) and put \n as record separator and \t (or any other delimiter) for field delimiter.
Create the target schema
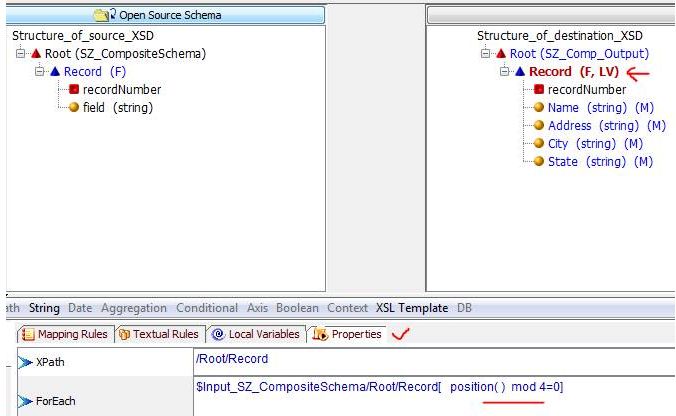
In mapping load the source and target schemas as shown here, in the record node of the target > properties > and double click on the record node of the Source schema and then put a predicate with open brackets as shown below.
Here mod 4 means that we are picking 4 fields as part of one data record.
In the record the mapping’s internal pointer is at the last field (State) and if we want to map the value of the field that is above in the list then we need to start from bottom position 0 to that field position. Thus Field that contains State is at position 0 and the Field that contains name is in position 3.
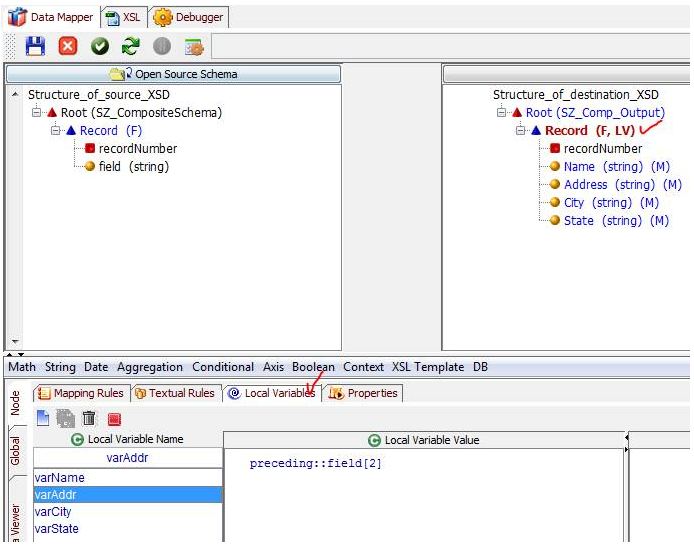
In the local variable tab create four variables and they will contain a rule like this:
varName preceding::field[3]
varAddress preceding::field[2]
varCity preceding::field[1]
varState field
Now click on the Name field of the target schema and then click on the variable and map it to the target field.

Comments
0 comments
Article is closed for comments.