
Issue - When the file size is large (say 160 MB), Text Schema remains in running state and process flow doesn't get executed.
Cause - This issue occurs because of inconsistency between Text Schema and Text file. For example, Text Schema configured "\r\n" as a record separator but Text file has only line separator and no record separator.
Due to this inconsistency in the record separator of both the file and the text schema, the Text Schema was not able to identify the records separately. And also Text file has only one line separator, due to this Text Schema takes the file as a single record which keeps loading data in memory. As a result, you are getting the Text Schema in running state issue.
Solution -
To avoid this issue, follow one of these steps:
- Change the record separator in text schema from "\r\n" to "\n" as it can parse both types of record separator in the file, OR
- Create the consistent text file with same record separators and define that accordingly in text schema
To check the separators in a text file, follow these steps:
- Open the file in Notepad++
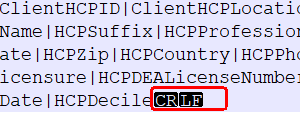
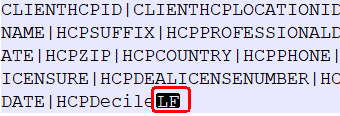
- Select "View -> Show Symbol -> Show all characters"
You can see the record separator in the file. Separator ‘CR’ means the record separator (\r) and ‘LF’ means the line separator (\n). When both are present then you need to define "\r\n" as a record separator in Text Schema otherwise only "\n".
Comments
0 comments
Please sign in to leave a comment.