
In this use case we will build a data integration orchestration that does the following:
1. Apply auto-map to map common fields between source and target elements
2. Filter or remove duplicate records from source data based on a For-each condition applied at target Record node
3. Split source data into two outputs based on a For-each condition in Mapping
4. Apply database lookups and discuss the use of value-maps
5. Build an orchestration based on the mapping and related source/target and schema activities
6. Trigger the process flow with File Event and see the results in the monitor dashboard
For examples on how to use Pivot and Joins please refer to their specific videos in the forum under the Use Case category.

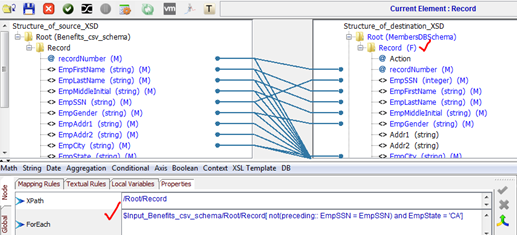
Important function in this mapping for duplicate handling and splitting is:
[ not(preceding:: EmpSSN = EmpSSN) and EmpState = 'CA']
Also refer to the walkthrough document, deployable solution zip and sample data file.
Comments
0 comments
Article is closed for comments.